Car Price Prediction Using Machine Learning

Machine learning models are becoming more common across a wide range of businesses as society becomes more dependent on technology. Machine learning is improving the automotive industry. Machine-learning algorithms, in particular, have been proven to be quite effective in assisting individuals and businesses in determining the value of their cars in the area of old car price prediction.
Old car price forecasting is an important component of the automotive industry since it assists individuals and corporations in determining the worth of their automobiles. This information is required for various purposes, including vehicle sales, insurance claims, and financial planning. However, evaluating the value of a used car can be difficult because it depends on various factors, including the make, model, year, mileage, and state of the car.
Machine learning models are useful in this situation. They may learn to identify patterns and trends in vast datasets of previous auto sales, which can then be used to forecast the value of a specific vehicle. These models can take into account the make, model, year, mileage, condition, and even the location of the car. This means that the estimated worth of a car can be very precise, giving people and companies important information they can use to make wise decisions. There are numerous different types of machine learning models that can be utilized to predict the price of used cars. The linear regression model is one of the most well-liked ones. To predict the value of a certain car, this model first finds the line of best fit through a dataset. Another well-liked paradigm is the decision tree model, which divides a dataset into progressively smaller subgroups in accordance with predetermined criteria. This procedure keeps going until the model makes a choice or a prediction.
In addition to these models, there are other more refined machine learning models, like neural networks and support vector machines. These algorithms can be very good at estimating the value of used cars because they can identify complex patterns and connections in the data.
In general, the automotive sector is using machine-learning models more frequently to anticipate the price of used cars. These algorithms may learn to identify patterns and trends in the data by examining vast datasets of previous automobile sales, which can then be used to forecast the value of a specific vehicle. For both individuals and companies, this information may be extremely helpful in guiding their decisions about the purchase, insurance, and financial planning of their automobiles. Machine learning models for predicting the price of used cars are going to get much more complex as technology develops.
Background
Several economies throughout the world depend heavily on the automotive sector, and the purchasing and selling of cars is a multi-billion dollar industry. Yet figuring out a used car’s worth can be difficult because it depends on so many different things, including the make, model, year, mileage, and condition of the car. Machine learning models have recently become a highly successful tool for estimating the worth of used automobiles, giving people and businesses useful information they can use to make wise decisions.
In order to help people and businesses assess the value of their vehicles, old car price forecast is a crucial component of the automotive industry.
This data is essential for various purposes, such as car sales, insurance claims, and financial planning. Yet estimating the value of a used car may be challenging because it depends on several variables, including the make, model, year, mileage, and state of the car.
In the past, figuring out the worth of a used car required performing a complicated series of calculations depending on the age, mileage, make, and model of the car. These computations, however, were frequently time-consuming and prone to mistakes, resulting in unreliable projections and possibly causing people and organisations to make bad judgements.
Machine learning algorithms have been a highly successful technique in recent years for estimating the value of used cars. These models can learn to identify patterns and trends in the data by analysing enormous datasets of historical automobile sales using cutting-edge algorithms. These algorithms may produce extremely precise projections of the value of a given vehicle by taking into account a wide range of criteria, including the make, model, year, mileage, condition, and even the location of the vehicle.
The capacity of machine learning models to account for a variety of parameters is one of the main benefits of using them to anticipate used car prices.
This covers not only the fundamental details of the vehicle’s make, model, and year but also more intricate details like its condition, the location of the transaction, and even its particular features and choices. This level of specificity enables incredibly precise valuation estimates for a specific vehicle, giving people and organisations useful data they may use to make wise decisions.
Another benefit of employing machine learning algorithms to anticipate used car prices is their ability to learn and adapt over time. These models can keep making predictions as new data becomes available, increasing the precision and dependability of their predictions over time. This indicates that people and companies can trust the forecasts made by these models because they are founded on the most recent and reliable data available.
In general, the automotive sector is using machine learning models more frequently to anticipate the price of used cars. These algorithms are quite good at estimating the worth of used cars, giving people and companies useful information they can use to make wise decisions. As technology develops, even more complex machine learning models will be created in the future for the prediction of used car prices, enhancing the precision and dependability of these predictions.
Diagram
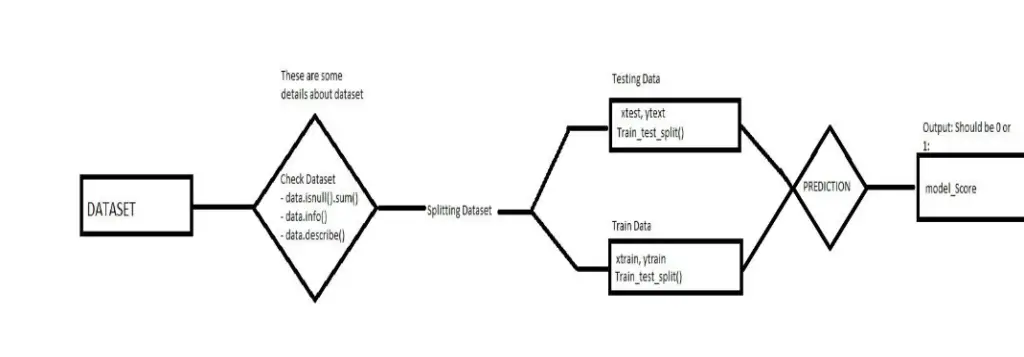
Correlations Output Diagram
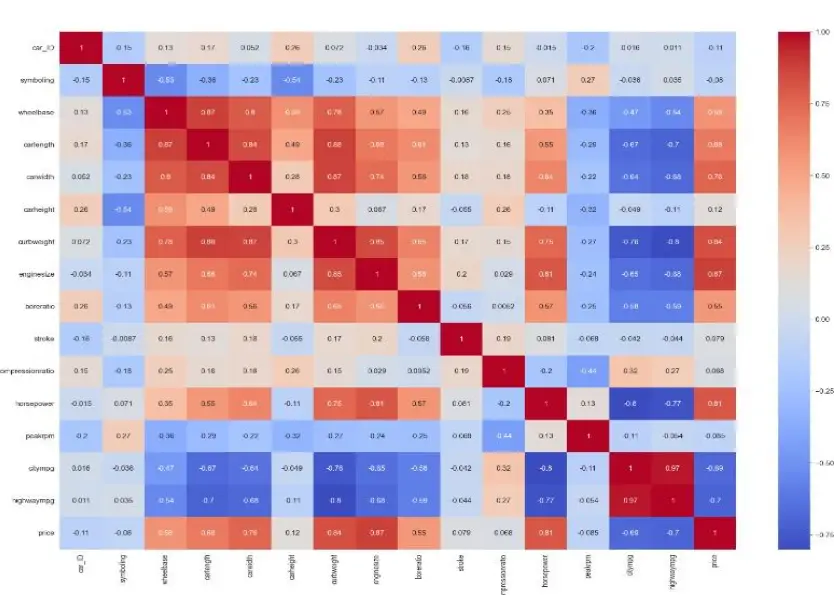
Explanation of Dataset
We picked the dataset “CarPrice” online. This dataset has the record of old cars to predict the price.
- No of rows: 206
- No of Columns:26
This dataset covers all the required information of the car to predict the car price.
car_ID | symboling | CarName | Fueltype | Aspiration | doornumber |
carbody | drivewheel | enginelocation | wheelbase | carlength | carwidth |
carheight | curbweight | enginetype | cylindernumber | Enginesize | Fuelsystem |
Boreratio | Stroke | compressionratio | Horsepower | Peakrpm | Citympg
|
Highwaym pg | price |
|
|
|
|
“Car Price” a dataset on old cars that can be used to estimate their market value. The dataset has 206 rows and 26 columns, indicating that there are 206 distinct cars and 26 different bits of information that can be used to estimate the prices of those cars. These columns are the perfect picture for the car to predict. Normally to predict car price we see his brand, name, condition, fuel type (diesel , petrol or other electric), horsepower and running of the car to get the better picture about price so this dataset has some external properties also like his shape, height, width, symbolling, wheelbase, curb weight, engine type, his cylinder number and some more mentioned above, these are the features , properties or some attributes our dataset has and our ml model need to predict the price of the car.
Feature Extraction Techniques
- Feature Scaling: It is a method for converting the data to a standard scale so that the various features may be compared.
- One-Hot Encoding: It is a method for turning numerical variables from category variables.
- Feature Selection: It is a method for selecting the dataset’s most pertinent characteristics in order to enhance model performance.
Different ML Models
- Linear Regression: It is a model that predicts the target variable based on the input features using a linear approach.
- Random Forest Regression: It’s a model that extrapolates from the input features to predict the target variable using an ensemble technique.
- Support Vector Regression: It is a model that predicts the target variable based on the input features using a non-linear technique.
Evaluation of the Models
- Mean Squared Error (MSE): It is a statistic used to assess how well the regression models perform.
- R-Squared (R^2): It is a statistic used to assess the regression models’ goodness of fit.
- Mean Absolute Error (MAE): It is a statistic used to assess the typical discrepancy between expected and observed values.
Conclusion
In conclusion, feature scaling and one-hot encoding can be utilized to preprocess the data for the vintage automobile price prediction dataset. The most pertinent features can also be chosen via feature selection. The data can be modelled using support vector regression, random forest regression, and linear regression. Metrics like MSE, R-Squared, and MAE can be used to assess the models’ performance.
Machine learning models can achieve a high level of accuracy in predicting car prices, especially when trained on comprehensive and up-to-date datasets. However, external factors and sudden market shifts can pose challenges.
Yes, one of the strengths of machine learning models is their ability to adapt to real-time changes in market conditions. This ensures that predictions remain relevant and up-to-date.
Consumers can benefit by making more informed decisions when buying or selling a car. Car price predictions provide transparency, enabling consumers to understand the fair market value of a vehicle.

Final Year Projects
Data Science Projects

Blockchain Projects

Python Projects

Cyber Security Projects

Web dev Projects

IOT Projects

C++ Projects
-
Where Do YouTubers Get Their Music?
-
Top 20 Machine Learning Project Ideas for Final Years with Code
-
Why Creators Choose YouTube: Exploring the Four Key Reasons
-
10 Advance Final Year Project Ideas with Source Code
-
10 Deep Learning Projects for Final Year in 2024
-
E Commerce sales forecasting using machine learning
-
AI Music Composer project with source code
-
Realtime Object Detection
-
30 Final Year Project Ideas for IT Students
-
Stock market Price Prediction using machine learning
-
c++ Projects for beginners
-
Python Projects For Final Year Students With Source Code
-
20 Exiciting Cyber Security Final Year Projects
-
10 Web Development Projects for beginners
-
Fake news detection using machine learning source code
-
Top 10 Best JAVA Final Year Projects
-
15 Exciting Blockchain Project Ideas with Source Code
-
C++ Projects with Source Code
-
Artificial Intelligence Projects For Final Year
-
Hand Gesture Recognition in python
