Fake news detection using machine learning source code

Sometimes, we have too much information and don’t know what is true or false. Fake news is when people lie or make mistakes on the internet. Fake news can make people confused or angry. Technology is getting better and brighter. It can help us find out what is fake and what is real. This article discusses fake news and how technology can help us stop it.
I will also provide source code for it, which you can use to make your own Fake news detection system using machine learning.
Fake News Detection Using Machine Learning
We want to know what’s real and what’s not. We have an intelligent system that can read text (like a message, tweet, or news story) and let us know how likely it is to be fake. The system is unique because it sees a lot of real and fake news from many different places and ways. Based on what it learned, the system can answer each word with either “yes” or “no.”
It can’t read words like we can. There must be numbers. So, we must find ways to turn the words into numbers. After that, we can use Naive Bayes, Logistic Regression, and Random Forests to teach the system and check its performance.
These algorithms must work better sometimes for the system to learn well. After that, we can use more complex methods like Attention or LSTM. These ways can help the computer read the words better.
Fake news detection using machine learning source code
To develop a fake news detection using machine learning, follow these steps.
Step 1: Download the dataset
This folder contains 2 datasets. One is for fake news, and the other is for actual news. The folder size is 43MB; you can download it here.
Step 2: Folder Structure
Extract both datasets and place them in the new folder. In the new folder, make a python file and open it with Vs. Code.The extenstion of file should be .py
Step 3: Import required libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from sklearn.metrics import accuracy_score, classification_report
Step 4: Load both datasets
Load both datasets using the pandas library and label them 0 and 1. For True new, label it as 0, and For Fake news, label it as 1
# Load true news dataset
true_df = pd.read_csv('True.csv')
true_df['label'] = 0 # Add a label column for true news
# Load fake news dataset
fake_df = pd.read_csv('Fake.csv')
fake_df['label'] = 1 # Add a label column for fake news
Step 5: Combine both datasets
# Combine the datasets
df = pd.concat([true_df, fake_df], ignore_index=True)
Step 6: Split the data into training and testing sets
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(df['text'], df['label'], test_size=0.2, random_state=42)
Step 7: Train the Model
model = make_pipeline(TfidfVectorizer(), MultinomialNB())
model.fit(X_train, y_train)
Step 8: Make predictions and Evaluate the model
# Make predictions on the test set
predictions = model.predict(X_test)
# Evaluate the model
accuracy = accuracy_score(y_test, predictions)
classification_report_result = classification_report(y_test, predictions)
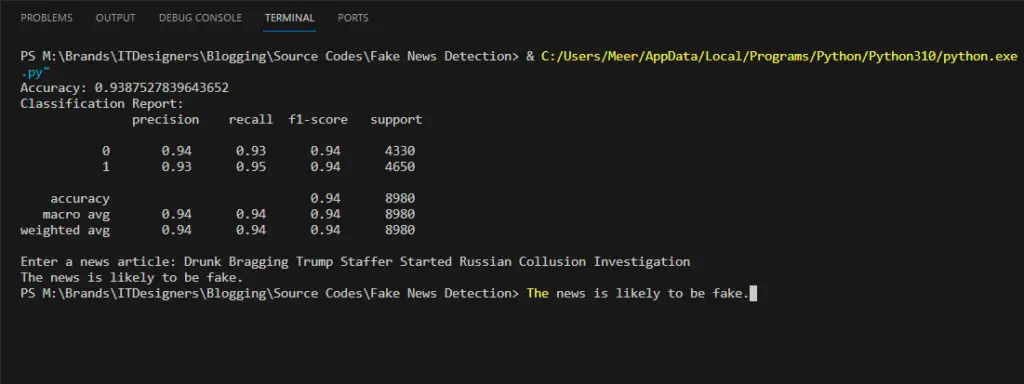
Step 9: Display results
# Display the result
print(f'Accuracy: {accuracy}')
print('Classification Report:\n', classification_report_result)
Step 10: User Input
By adding this step we can give input of our choice give input from the list of datasets it will tell if the news is fake or true
Take input from the user
user_input = input("Enter a news article: ")
# Make a prediction
prediction = model.predict([user_input])
# Display the result
if prediction[0] == 0:
print("The news is likely to be true.")
else:
print("The news is likely to be fake.")
Output
External Links for Further Exploration
While machine learning greatly improves fake news identification, complete elimination remains a difficult task. Human interaction and critical thinking are necessary when working with machine learning algorithms.
Machine learning models should be updated on a regular basis to reflect changing language trends and new methods used by fake news publishers. Continuous learning is crucial.
Yes, individuals play an important role as key users of knowledge. Reporting suspicious content and improving media literacy are helpful approaches to help struggle false news.

Final Year Projects
Data Science Projects

Blockchain Projects

Python Projects

Cyber Security Projects

Web dev Projects

IOT Projects

C++ Projects
-
Where Do YouTubers Get Their Music?
-
Top 20 Machine Learning Project Ideas for Final Years with Code
-
Why Creators Choose YouTube: Exploring the Four Key Reasons
-
10 Advance Final Year Project Ideas with Source Code
-
10 Deep Learning Projects for Final Year in 2024
-
AI Music Composer project with source code
-
Realtime Object Detection
-
30 Final Year Project Ideas for IT Students
-
E Commerce sales forecasting using machine learning
-
Stock market Price Prediction using machine learning
-
c++ Projects for beginners
-
Python Projects For Final Year Students With Source Code
-
20 Exiciting Cyber Security Final Year Projects
-
10 Web Development Projects for beginners
-
Fake news detection using machine learning source code
-
Top 10 Best JAVA Final Year Projects
-
15 Exciting Blockchain Project Ideas with Source Code
-
C++ Projects with Source Code
-
Artificial Intelligence Projects For Final Year
-
Hand Gesture Recognition in python
-
Best 21 Projects Using HTML, CSS, Javascript With Source Code
-
Credit Card Fraud detection using machine learning
-
How to Download image in HTML
-
10 advanced JavaScript project ideas for experts in 2024
-
Hate Speech Detection Using Machine Learning
-
How to Host HTML website for free?
-
20 Advance IOT Projects For Final Year in 2024
-
Python Projects For Beginners with Source Code
-
Plant Disease Detection using Machine Learning
-
Ethical Hacking Projects
-
Data Science Projects with Source Code
-
Best Machine Learning Final Year Project
-
Top 7 Cybersecurity Final Year Projects in 2024
-
Best 13 IOT Project Ideas For Final Year Students
-
10 Exciting C++ projects with source code in 2024
-
Top 13 IOT Projects With Source Code
-
Artificial Intelligence Projects for the Final Year
-
portfolio website using javascript
-
Phishing website detection using Machine Learning with Source Code
-
10 Exciting Next.jS Project Ideas
-
17 Easy Blockchain Projects For Beginners
-
Fabric Defect Detection
-
Heart Disease Prediction Using Machine Learning
-
How to Change Color of Text in JavaScript
-
Diabetes Prediction Using Machine Learning
-
Wine Quality Prediction Using Machine Learning
-
10 Final Year Projects For Computer Science With Source Code
-
Car Price Prediction Using Machine Learning
-
Step-By-Step Complete Guide Of Freelance Visa Abu Dhabi In 2024
-
10 TypeScript Projects With Source Code
