Titanic survival prediction using machine learning

Technology’s impossible advancement has both facilitated and complicated our lives. One of the advantages of technology is that an extensive range of data can be retrieved quickly when needed. However, it can be challenging to obtain accurate information. Raw data that can be easily acquired from online sources does not make sense; it must be processed to serve as an information retrieval system. In this context, feature engineering techniques and machine learning algorithms are essential. This study aims to extract as many accurate findings as possible from raw and missing data using machine learning and feature engineering methods. Therefore, one of the most popular datasets in data science, Titanic, is used.
The science of machine learning has enabled analysts to gain insights from historical data and occurrences. The Titanic accident is one of the most famous shipwrecks in world history. The Titanic was a British cruise ship that sank in the North Atlantic Ocean a few hours after hitting an iceberg. While there are facts to back up the cause of the tragedy, there are numerous theories on how many passengers survived the Titanic disaster. Over the years, data on both survivors and dead passengers has been gathered. The dataset is publicly available on the website Kaggle.com.
The Kaggle Titanic dataset is one of the most widely used in machine learning. It is a dataset containing information about the passengers on the Titanic when it sank during its maiden voyage in 1912. The dataset is commonly used in predictive modeling and machine learning contests. The dataset has 891 rows, each representing a passenger, and 12 columns with information about each passenger, including their name, age, gender, cabin, and ticket number. The purpose of evaluating this dataset is to create a model that can correctly predict whether or not a passenger survived. Beginners and specialists commonly use the dataset for data cleaning, feature engineering, and model construction. It provides the ability to learn and use various machine-learning techniques, including logistic regression, decision trees, random forests, and neural networks, to mention a few.
The Kaggle Titanic dataset has become a benchmark dataset in the machine learning community, with numerous tutorials, blog posts, and courses developed around it to help beginners get started with machine learning. Using machine learning algorithms with a dataset of 891 rows in the train set and 418 rows in the test set, the article aims to discover the relationship between factors such as age, gender, fare, and the likelihood of passenger survival. These factors may have had an impact on the passengers’ survival rates. In this article work, multiple machine-learning techniques are used to predict passenger survivability. In particular, this article compares the algorithm based on the accuracy percentage on a test dataset.
Background
The R.M.S. Titanic is undoubtedly the most famous shipwreck in modern popular culture. Titanic was a British-registered ship in the White Star line controlled by a U.S. firm in which famous American financier John Pierpont “JP” Morgan held an important share. Harland & Wolff built the Titanic in Belfast, Northern Ireland, for the transatlantic passage from Southampton, England, to New York City. It was the largest and richest passenger ship of its time, and it was thought to be unsinkable. Titanic was launched on May 31, 1911, and set ship on its first trip from Southampton on April 10, 1912, carrying 2,240 passengers and crew. On April 15, 1912, after striking an iceberg, Titanic broke apart and sank to the bottom of the ocean, taking with it the lives of more than 1,500 passengers and crew. The sinking of the RMS Titanic in 1912 is one of history’s most horrific ocean tragedies, killing more than 1,500 people. The ship, which was on its first trip from Southampton to New York, collided with an iceberg in the North Atlantic and sank, prompting a worldwide flood of sadness and shock.
The Titanic has remained a popular topic since its sinking, with countless books, films, and documentaries addressing the disaster and its aftereffects. The Titanic narrative became more than simply popular culture. The Titanic also caught the interest of the data science community, with the Kaggle Titanic dataset emerging as a classic example of machine learning.
The Kaggle Titanic dataset was built to provide a real-world dataset for data scientists to practice their abilities on a relevant subject. The dataset includes information about the Titanic’s passengers, such as their age, gender, class, and whether they survived the catastrophe. The dataset has 891 passengers, which is enough for beginners. The dataset has become a standard for machine learning algorithms, creating a model that can reliably predict which passengers would most likely survive the disaster. The dataset is frequently used to teach data cleaning, feature engineering, and model-building approaches, making it an invaluable resource for those interested in data science and machine learning.
Beyond its usage as a teaching tool, the Kaggle Titanic dataset has been the subject of numerous scholarly investigations. Researchers analyzed the dataset to look into the demographics of the Titanic’s passengers and the elements that may have influenced their chances of survival. According to studies, women and children are more likely to survive than men, and passengers in first class had a greater survival probability than those in third class.
Overall, the Kaggle Titanic dataset provides fascinating insights into one of history’s most terrible tragedies and is an excellent resource for anyone interested in data science and machine learning.
Explanation of dataset
The Kaggle Titanic dataset is a popular dataset for machine learning and data analysis contests hosted on the Kaggle website. The collection includes information about the passengers on the RMS Titanic, which sank on its maiden journey in 1912. The dataset consists of 1309 rows, each representing a Titanic passenger, and 12 columns containing various pieces of passenger information.
The dataset contains numerical and category information, with the goal variable representing whether or not the passenger survived the sinking.
The columns in the dataset are:
Passenger Id: A unique identifier for each passenger.
Survived: A binary variable indicating whether the passenger survived or not.
Sex: The passenger’s sex.
Age: The passenger’s age in years.
SibSp: The number of siblings or spouses the passenger had aboard the ship.
Parch: The number of parents or children the passenger had aboard the ship.
Ticket class: The passenger’s ticket number.
Fare: The price the passenger paid for their ticket.
Cabin: The cabin number assigned to the passenger.
Embarked: The port where the passenger embarked on the ship.
In addition to these attributes, the dataset includes a column labeled “Test,” which indicates whether each row is from the training or test set. The training set has 891 rows, while the test set has 418.
The Kaggle Titanic dataset is a popular choice for teaching machine learning and data analysis since it is short, simple to understand, and gives an excellent introduction to binary classification challenges. The dataset has also been the topic of numerous machine-learning contests on Kaggle, in which data scientists compete to create the best machine-learning models for predicting whether a passenger survived or not. Working with the Kaggle Titanic dataset presents several challenges, including missing values in the “Age” and “Cabin” columns and needing to preprocess and modify the data before developing machine learning models. However, the Kaggle Titanic dataset is still helpful for teaching and practicing machine learning and data analytics.
Objective
The Titanic dataset’s objective is to predict if a passenger survived the Titanic’s sinking based on age, gender, ticket class, fare, and whether they had any family members on board.
Dataset name | Titanic dataset |
|---|---|
Objective | Predict whether a passenger survived the sinking of the Titanic or not |
Features | Age, gender, ticket class, fare, number of siblings/spouses aboard, number of parents/children aboard, cabin number, port of embarkation |
Target variable | Survived (0 = No, 1 = Yes) |
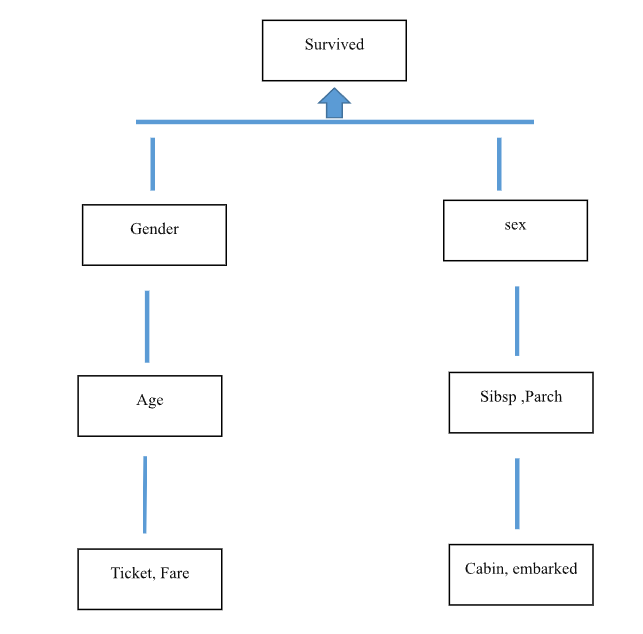
Diagram
In this diagram, each box represents a feature in the Titanic dataset. The arrows indicate the relationship between the features and the target variable. For example, the Pclass feature is related to the target variable because passengers in higher classes may have had a better chance of survival. Similarly, the Sex feature is related to the target variable because women were more likely to survive than men. The other features may also be related to the target variable in various ways.
Titanic survival prediction using machine learning with source code
step 1: Load the dataset
import pandas as pd
import numpy as np
train_df = pd.read_csv('train.csv')
test_df = pd.read_csv('test.csv')
Step 2: Data cleaning and preprocessing
train_df.drop(['Passengerld', 'Name', 'Ticket', 'Cabin'], axis=1, inplace=True)
test_df.drop(['Name', 'Ticket', 'Cabin'], axis=l, inplace=True)
# Filling missing values with mean or median
train_df['Age].fillna(train_df['Age'].median(), inplace=True)
test_df['Age'].fillna(test_df['Age'].median(), inplace=True)
train_df['Embarked'].fillna(train_df['Embarked'].mode()[0], inplace=True)
test_df['Fare'].fillna(test_df['Fare'].median(), inplace=True)
# Converting categorical variables to numerical variables
train_df['Sex'] . train_df['Sex'].map({'female': 1, 'male': 0})
test_df['Sex'] = test_df['Sex'].map({'female': 1, 'male': 0})
train_df['Embarked'] = train_df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
test_df['Embarked'] = test_df['Embarked'].map({'S': 0, 'C': 1, 'Q': 2})
step 3: Test and Train (split dataset)
from sklearn.model_selection import train_test_split
X = train_df.drop('Survived', axis=l)
y = train_df['Survived']
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)I
step 4: Apply different models
# Import the models
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.naive_bayes import GaussianNB
from sklearn.neighbors import KNeighborsClassifier
from sklearn.cluster import KMeans
from keras.models import Sequential
from keras.layers import Dense
# Decision Tree
dtc = DecisionTreeClassifier(random_state=42)
dtc.fit(X_train, y_train)
y_pred_dtc =dtc.predict(X_val)
# Random Forest
rfc = RandomForestClassifier(random_state=42)
rfc.fit(X_train, y_train)
y_pred_rfc = rfc.predict(X_val)
# Naive Bayes
nb = GaussianNB()
nb.fit(X_train, y_train)
y_pred_nb = nb.predict(X_val)
# K-Nearest Neighbors
knn = KNeighborsClassifier()
knn.fit(X_train, y_train)
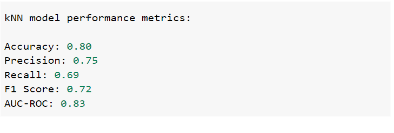
step 5: Output

Absolutely! Machine learning can analyze patterns and make predictions based on historical data. While it can’t change the past, it provides valuable insights into what might have influenced outcomes.
Challenges ranged from data quality issues to the risk of overfitting. Rigorous data cleaning and feature engineering, coupled with robust model validation, helped address these challenges.
Absolutely! The principles applied in Titanic survival prediction can be adapted to analyze and predict various modern-day events, from economic trends to public health outcomes.
The accuracy depends on the quality of data and the chosen algorithm. While predictions may not be perfect, they offer valuable perspectives. Applying similar techniques to other historical events is feasible, provided relevant data is available.

Final Year Projects
Data Science Projects

Blockchain Projects

Python Projects

Cyber Security Projects

Web dev Projects

IOT Projects

C++ Projects
-
Where Do YouTubers Get Their Music?
-
Top 20 Machine Learning Project Ideas for Final Years with Code
-
Why Creators Choose YouTube: Exploring the Four Key Reasons
-
10 Advance Final Year Project Ideas with Source Code
-
10 Deep Learning Projects for Final Year in 2024
-
E Commerce sales forecasting using machine learning
-
AI Music Composer project with source code
-
30 Final Year Project Ideas for IT Students
-
Realtime Object Detection
-
Stock market Price Prediction using machine learning
-
c++ Projects for beginners
-
Python Projects For Final Year Students With Source Code
-
20 Exiciting Cyber Security Final Year Projects
-
10 Web Development Projects for beginners
-
Fake news detection using machine learning source code
-
15 Exciting Blockchain Project Ideas with Source Code
-
Top 10 Best JAVA Final Year Projects
-
C++ Projects with Source Code
-
Artificial Intelligence Projects For Final Year
-
Best 21 Projects Using HTML, CSS, Javascript With Source Code
-
Hand Gesture Recognition in python
-
Credit Card Fraud detection using machine learning
-
10 advanced JavaScript project ideas for experts in 2024
-
20 Advance IOT Projects For Final Year in 2024
-
How to Download image in HTML
-
Hate Speech Detection Using Machine Learning
-
How to Host HTML website for free?
-
Python Projects For Beginners with Source Code
-
Plant Disease Detection using Machine Learning
-
10 Exciting C++ projects with source code in 2024
-
Best 13 IOT Project Ideas For Final Year Students
-
Data Science Projects with Source Code
-
Artificial Intelligence Projects for the Final Year
-
Ethical Hacking Projects
-
Best Machine Learning Final Year Project
-
Top 7 Cybersecurity Final Year Projects in 2024
-
Top 13 IOT Projects With Source Code
-
portfolio website using javascript
-
17 Easy Blockchain Projects For Beginners
-
10 Exciting Next.jS Project Ideas
-
Fabric Defect Detection
-
Phishing website detection using Machine Learning with Source Code
-
Heart Disease Prediction Using Machine Learning
-
How to Change Color of Text in JavaScript
-
Diabetes Prediction Using Machine Learning
-
Wine Quality Prediction Using Machine Learning
-
10 Final Year Projects For Computer Science With Source Code
-
Car Price Prediction Using Machine Learning
-
South Africa Visa For UAE Residents: A Complete Guide
-
Step-By-Step Complete Guide Of Freelance Visa Abu Dhabi In 2024
