Hate Speech Detection Using Machine Learning

Today, the world of the internet and social media provides a platform where people freely express their opinions and thoughts in text form. But some people used their freedom in the wrong way to direct hate towards individuals for race, religion and many more things. For this, cyber security organizations increase the number of cases day by day for cyberbullying. Also, many organizations have found a solution to detect hateful speech. So, in the digital era machine learning is now important for detecting hate speech. In this article, we will examine the concept of hate speech, the issues associated with detecting it, and how machine learning can help.
What is Hate Speech?
Hate speech is defined as any speech, act, behavior, writing, or display that may cause violence or adverse action against or by a specific individual or group or that criticism or threatens a specific individual or group because of characteristics such as race, ethnicity, religion, sexual orientation, disability, or gender.
The Challenges in Detecting Hate Speech
Because hate speech is constantly changing and language is personal, it can be challenging to identify it. Because hate speech can appear in various ways and settings, it can be challenging to define and recognize. Furthermore, hate speech can also be hidden and sensitive, which makes it harder to recognize using normal methods.
Machine Learning and Hate Speech Detection
It is possible to train machine learning algorithms to detect patterns in text data and, using these patterns, identify hate speech. More accurate detection is made possible by machine learning algorithms that can distinguish between hate speech and non-hate speech through the analysis of vast datasets of text data. So, for this, you should train the machine learning model for an accurate dataset.
The Future of Hate Speech Detection
The identification of hate speech appears to have a bright future as long as technology keeps developing. Machine learning algorithms are evolving and getting better at accurately identifying hate speech. Furthermore, complicated text data analysis and comprehension are becoming more straightforward due to advances in natural language processing. We hope these developments will create a more secure and welcoming online community.
How to build Hate Speech Detection using Machine Learning?
To build hate speech detection system in python you need to follow these steps.
Step 1: Download dataset
First of all, you need to download the dataset. This dataset contains multiple tweets. And our system will identify if a tweet is offensive or not. You can download the dataset from here. Download here: twitter_dataset

Step 2: Import Libraries
These lines import the necessary libraries for data manipulation (pandas and numpy), text processing (nltk), and machine learning (sklearn).
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import re
import nltk
from nltk.util import pr
Step 3: Initializing Stemmer and Stopwords
Here, we initialize a stemmer and stopwords. The stemmer is used to reduce words to their base form, and stopwords are words that are commonly used in a language and are not considered significant for analysis.
stemmer=nltk.SnowballStemmer("english")
from nltk.corpus import stopwords
import string
stopword=set(stopwords.words("english"))
Step 4: Loading the Data
This line loads the dataset from the CSV file “twitter_data.csv” into a pandas DataFrame called data.
data=pd.read_csv("twitter_data.csv")
Step 5: Preprocessing the Data
These lines create a new column called labels based on the class column. The class column is mapped to the corresponding label (0 to “Hate speech”, 1 to “Not offensive”, and 2 to “Neutral”). Then, we select only the tweet and labels columns for further processing.
data['labels']=data['class'].map({0:"Hate speech",1:"Not offensive",2:"Neutral"})
data = data[["tweet","labels"]]
Step 6: Tokenization and Stemming
This function tokenizes the text (splits it into words), removes stopwords and non-alphabetic characters, and then stems the words using the stemmer.
def tokenize_stem(text):
tokens = nltk.word_tokenize(text)
tokens = [word for word in tokens if word not in stopword]
tokens = [word for word in tokens if word.isalpha()]
tokens = [stemmer.stem(word) for word in tokens]
return tokens
Step 7: Vectorization
This code creates a CountVectorizer object with the tokenize_stem function as the tokenizer. It then fits and transforms the tweet column of the data DataFrame into a sparse matrix X.
vectorizer = CountVectorizer(tokenizer=tokenize_stem)
X = vectorizer.fit_transform(data['tweet'])
Step 8: Splitting the Data
This line splits the data into training and testing sets. X_train and y_train contain the features and labels for the training set, while X_test and y_test contain the features and labels for the testing set.
X_train, X_test, y_train, y_test = train_test_split(X, data['labels'], test_size=0.2, random_state=42)
Step 9: Training the Classifier
This code creates a DecisionTreeClassifier object and trains it on the training data.
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
Step 10: Taking User Input
This line prompts the user to enter a tweet.
tweet = input("Enter your tweet: ")
Step 11: Vectorizing User Input:
This code vectorizes the user input tweet using the same CountVectorizer object.
tweet_vector = vectorizer.transform([tweet])
Step 12: Predicting the Label
This line uses the trained classifier to predict the label for the user input tweet.
prediction = classifier.predict(tweet_vector)
Step 12: Predicting the Label
This line prints the predicted label for the user input tweet.
print(f"The tweet is classified as: {prediction[0]}")
Complete Source Code for Hate Speech Detection Using Machine Learning
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
import re
import nltk
from nltk.util import pr
stemmer=nltk.SnowballStemmer("english")
from nltk.corpus import stopwords
import string
stopword=set(stopwords.words("english"))
# Load the data
data=pd.read_csv("twitter_data.csv")
# Preprocess the data
data['labels']=data['class'].map({0:"Hate speech",1:"Not offensive",2:"Neutral"})
# Select relevant columns
data = data[["tweet","labels"]]
# Tokenization and stemming
def tokenize_stem(text):
tokens = nltk.word_tokenize(text)
tokens = [word for word in tokens if word not in stopword]
tokens = [word for word in tokens if word.isalpha()]
tokens = [stemmer.stem(word) for word in tokens]
return tokens
# Vectorize the text
vectorizer = CountVectorizer(tokenizer=tokenize_stem)
X = vectorizer.fit_transform(data['tweet'])
# Split the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, data['labels'], test_size=0.2, random_state=42)
# Train the classifier
classifier = DecisionTreeClassifier()
classifier.fit(X_train, y_train)
# Take input from the user
tweet = input("Enter your tweet: ")
# Vectorize the user input
tweet_vector = vectorizer.transform([tweet])
# Predict the label
prediction = classifier.predict(tweet_vector)
# Print the prediction
print(f"The tweet is classified as: {prediction[0]}")
Output
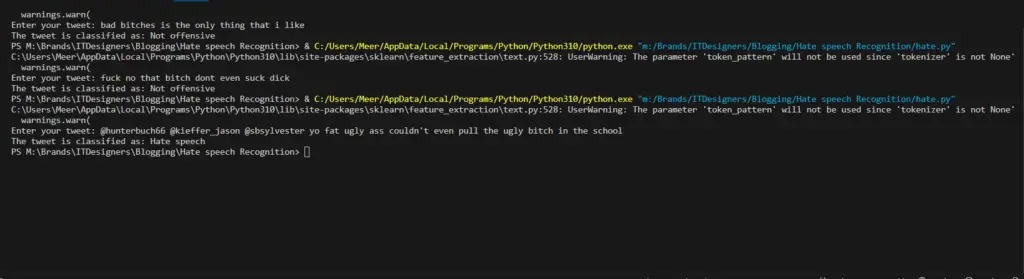
Hate speech is a big issue that affects people and communities. Using machine learning to identify and stop hate speech can make the internet safer and more welcoming for everyone. With advancing technology, we can make more progress in fighting against hate speech.
Helping Material for Hate Speech Detection system
Machine learning algorithms analyze vast quantities of text data to detect patterns and trends that could suggest hate speech. The algorithms can then flag potentially hazardous content for human inspection.
Hate speech can be subtle and context-dependent, making it difficult to detect. Furthermore, hate speech changes over time, making it difficult for computers to stay up.
Individuals can fight hate speech by reporting harmful content, educating others on the consequences of hate speech, and supporting diversity and tolerance.

Final Year Projects
Data Science Projects

Blockchain Projects

Python Projects

Cyber Security Projects

Web dev Projects

IOT Projects

C++ Projects
-
Where Do YouTubers Get Their Music?
-
Top 20 Machine Learning Project Ideas for Final Years with Code
-
Why Creators Choose YouTube: Exploring the Four Key Reasons
-
10 Advance Final Year Project Ideas with Source Code
-
10 Deep Learning Projects for Final Year in 2024
-
E Commerce sales forecasting using machine learning
-
AI Music Composer project with source code
-
Realtime Object Detection
-
30 Final Year Project Ideas for IT Students
-
Stock market Price Prediction using machine learning
-
c++ Projects for beginners
-
Python Projects For Final Year Students With Source Code
-
20 Exiciting Cyber Security Final Year Projects
-
10 Web Development Projects for beginners
-
Fake news detection using machine learning source code
-
Top 10 Best JAVA Final Year Projects
-
15 Exciting Blockchain Project Ideas with Source Code
-
C++ Projects with Source Code
-
Artificial Intelligence Projects For Final Year
-
Hand Gesture Recognition in python
-
Best 21 Projects Using HTML, CSS, Javascript With Source Code
-
Credit Card Fraud detection using machine learning
-
How to Download image in HTML
-
10 advanced JavaScript project ideas for experts in 2024
-
Hate Speech Detection Using Machine Learning
-
How to Host HTML website for free?
-
20 Advance IOT Projects For Final Year in 2024
-
Python Projects For Beginners with Source Code
-
Plant Disease Detection using Machine Learning
-
Ethical Hacking Projects
-
Data Science Projects with Source Code
-
10 Exciting C++ projects with source code in 2024
-
Best Machine Learning Final Year Project
-
Top 7 Cybersecurity Final Year Projects in 2024
-
Best 13 IOT Project Ideas For Final Year Students
-
Top 13 IOT Projects With Source Code
-
Artificial Intelligence Projects for the Final Year
-
portfolio website using javascript
-
Phishing website detection using Machine Learning with Source Code
-
Fabric Defect Detection
-
10 Exciting Next.jS Project Ideas
-
17 Easy Blockchain Projects For Beginners
-
Heart Disease Prediction Using Machine Learning
-
How to Change Color of Text in JavaScript
-
Diabetes Prediction Using Machine Learning
-
Wine Quality Prediction Using Machine Learning
-
10 Final Year Projects For Computer Science With Source Code
-
Car Price Prediction Using Machine Learning
-
Step-By-Step Complete Guide Of Freelance Visa Abu Dhabi In 2024
-
South Africa Visa For UAE Residents: A Complete Guide
